EventLoop of Browser
在了解EventLoop之前,首先再稳固一下JavaScript代码的执行机制
JavaScript 执行顺序
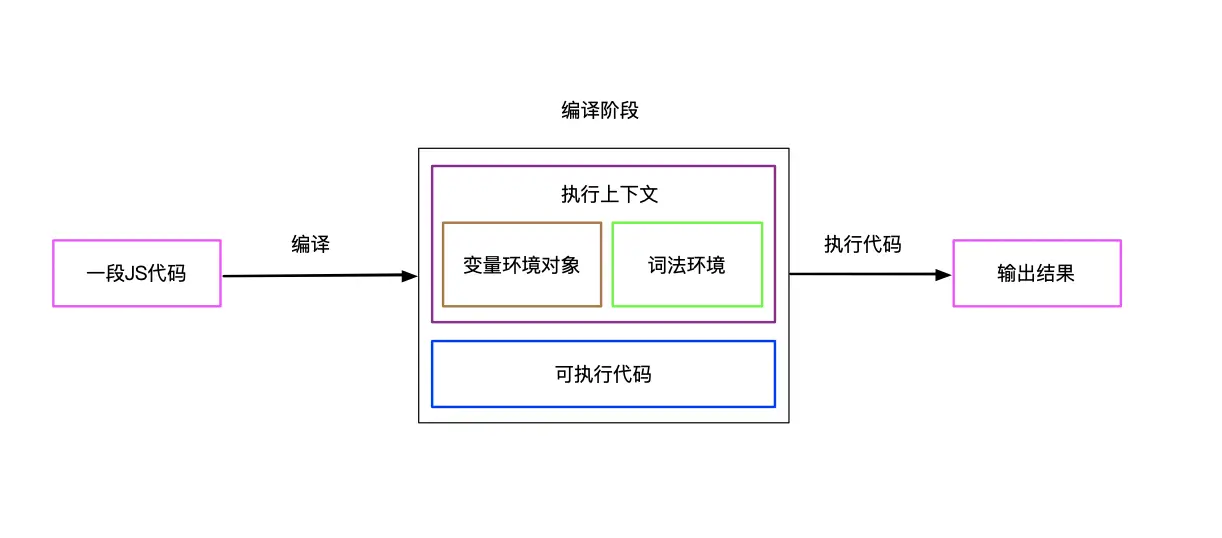
在遇到一段JS代码时,它的执行顺序表面看是按照顺序执行,但是内部其实不然。 一段JS在执行之前,首先会被编译器进行编译,之后会在JS引擎的控制下执行代码
执行上下文
编译阶段
在一段代码编译之后,会生成两部分内容:
- 执行上下文 - 当前JS代码执行的运行环境
- 可执行代码
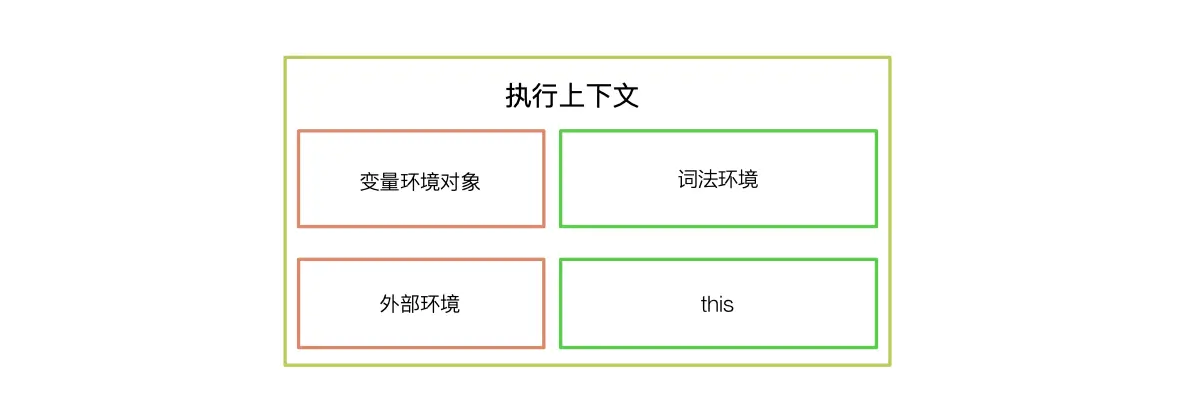
执行上下文
执行上下文中又包含了变量环境对象(variable environment)和词法环境
变量环境对象中包含了这段代码中所有的声明。
foo();console.log(bar);var bar = 3;function foo() {console.log('excute fo');}
分析上面的🌰:
// 环境变量 对象variable environment {bar -> undefinedfoo -> function() { ... }}
在执行阶段,JS引擎会按照顺序执行可执行代码。
执行上下文
执行上下文是在编译阶段产生的,在什么情况下会创建执行上下文呢?
-
全局执行上下文 - 执行全局代码
-
函数执行上下文 - 执行函数代码
-
eval执行上下文 - 执行eval函数
调用栈
调用栈又称为执行上下文栈 - 管理执行上下文的栈
下面通过简单的例子来说明调用栈
var a = 2;function addAll(b) {return add(x, y)}function add(a, b) {return a + b}addAll(5)
首先编译全局代码产生全局执行上下文,全局执行上下文入栈,其变量环境对象为:
variable environment {a -> undefinedaddAll -> function() { add(x, y) }add -> function() { return a + b }}
接着执行全局可执行代码:a = 2, addAll();
在执行addAll函数时,编译产生了addAll执行上下文栈,入栈,其变量环境对象为:
variable environment {... // 为空}
下一步执行addAll中可执行代码 add函数,进行编译之后产生了add执行上下文栈,入栈,变量环境对象依然为空。执行add中的可执行代码。
执行完毕之后,调用栈弹出add执行上下文,紧接着又弹出addAll执行上下文,最终调用栈中只有全局执行上下文
调用栈可以查看代码的执行顺序,以及代码之间的调用关系,排查bug是非常便捷的
栈溢出
调用栈也是有大小的,栈溢出这种问题在开发中出现的概率也不小。如果函数递归调用并且没有结束条件的时候,通常会产生栈溢出
初探事件循环、消息队列
缘由: 渲染进程都会有一个主线程,而这个主线程会处理不同的任务,DOM渲染,计算样式,脚本执行,用户输入,异步任务等
- 在单线程中处理已安排好的任务
function MainThread() {const a = 1 + 1;const b = 2/1;const c = 4*3;console.log(a,b,c)}
- 在单线程中处理新加入的任务
要在线程运行的过程中处理新加入的任务,就需要采用事件循环机制了
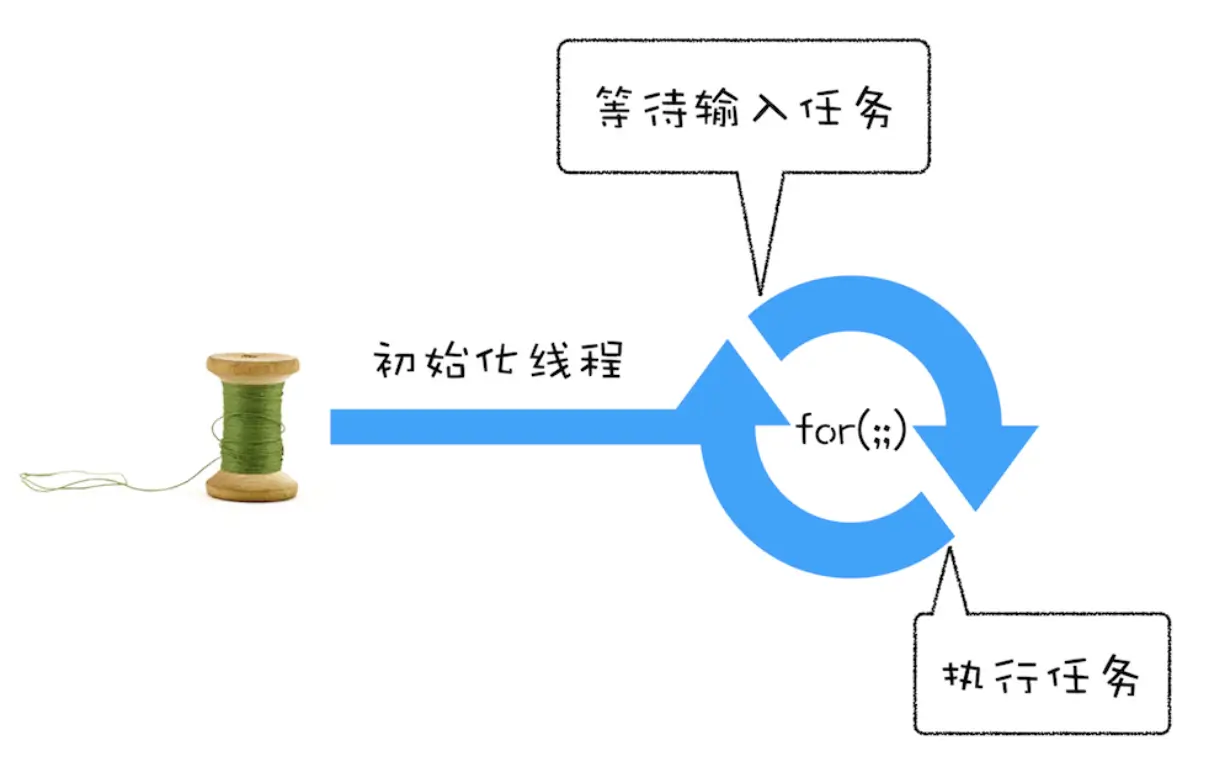
function getInput(val) {return val}// 主线程 等待用户的输入function MainThread() {for(;;) {let firstNum = getInput(3)let secondNum = getInput(4)console.log(firstNum + secondNum)}}
- 在单线程中处理其他线程发送的任务
用第二版线程是无法处理其他线程发送的任务的,因此,消息队列就产生了
消息队列
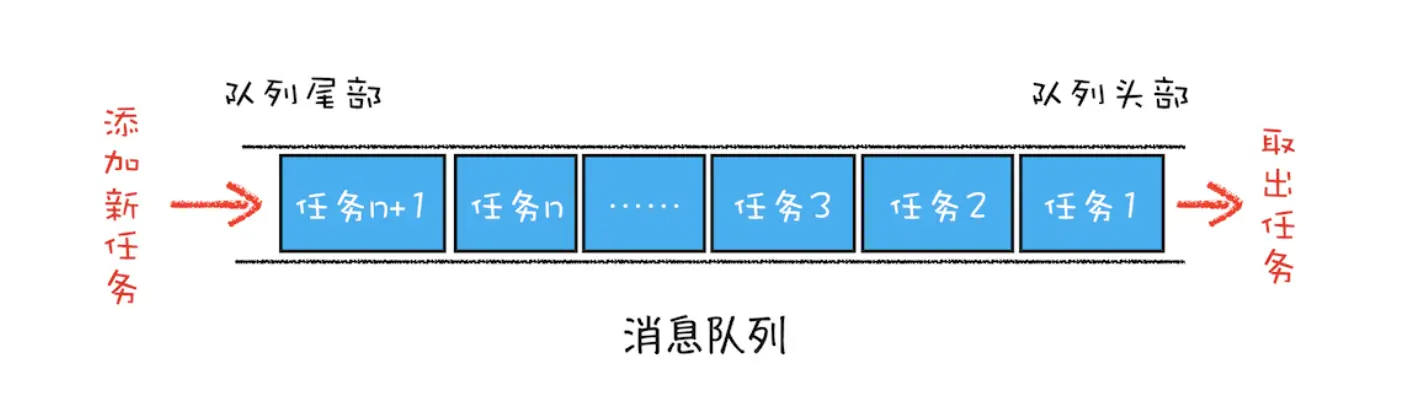
消息队列中有很多的任务类型(输入事件-鼠标滚动、点击、移动,微任务,文件读写、websocket、定时器等), 每当有新的线程的任务来的时候,就会进入到消息队列中,等待主线程中的任务执行完成之后再执行。
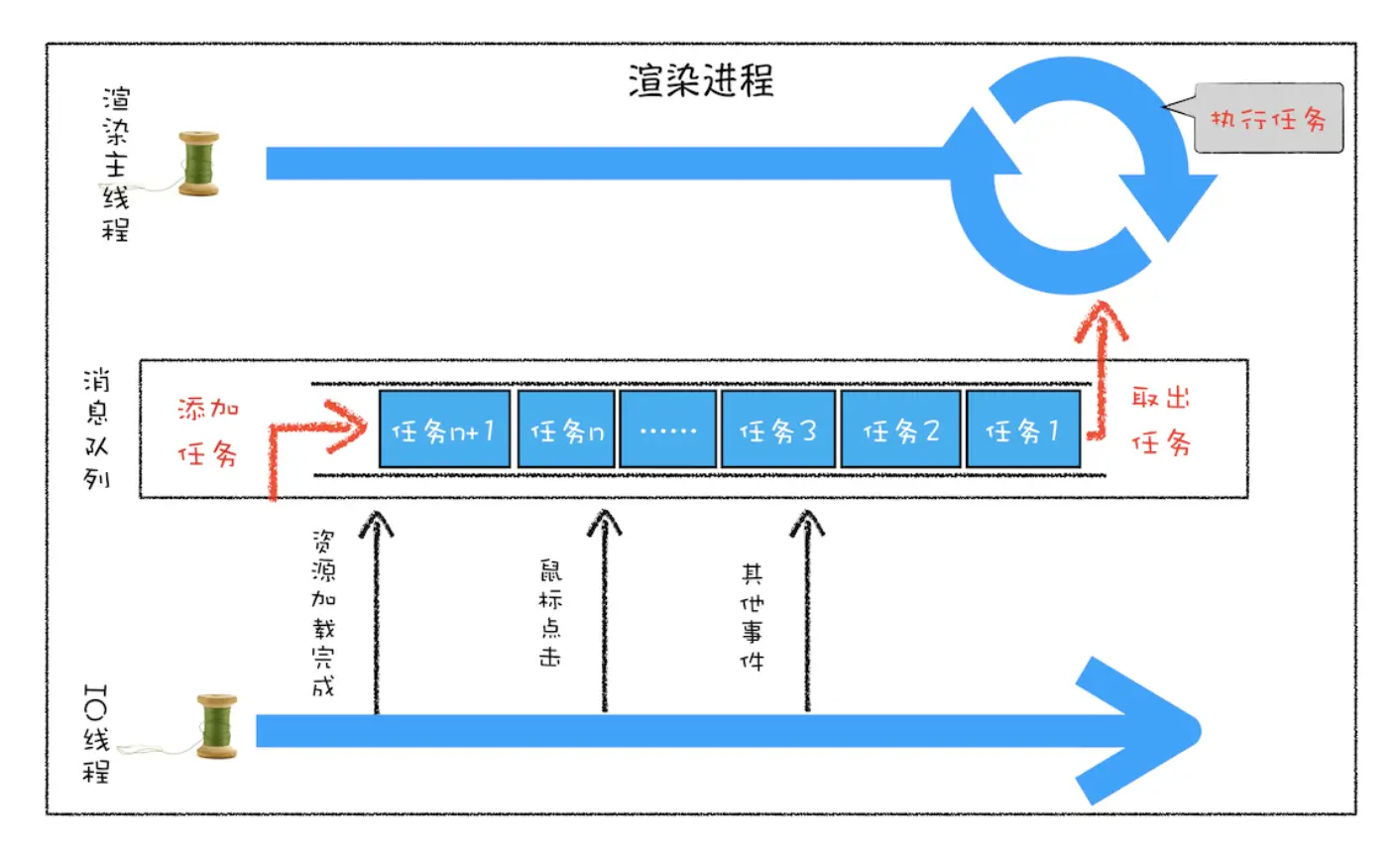
页面使用单线程的缺点
- 处理优先级高的任务
比较典型的场景就是监控DOM节点变化的情况,通用的做法是利用JavaScript设计一套监听系统,当数据变化时,渲染引擎同步调用接口,也就是典型的观察者模式
- 当DOM频繁的调用时,直接调用渲染的接口主线程执行,会导致任务执行时间的拉长,从而导致执行效率的下降
- 如果把DOM变化成异步操作加入到队列里,又失去了监控的时效性
基于上述两点,微任务出现了
通常将消息队列中的任务称为宏任务,每个宏任务中包含一个微任务队列,在执行宏任务的过程中,如果有DOM有变化,会将这些操作DOM的操作保存在微任务中,这样就解决了实时性问题
- 如何解决单个任务执行时间过长问题
因为所有任务都是在单线程中执行的,如果某个任务执行的时间过长,则会影响用户的体验。
所以浏览器采用了回调的方式来规避这种问题
事件循环setTimeout
从上述知道了浏览器页面是由事件循环和消息队列来驱动。
在这部分主要学习事件循环的应用,典型的有setTimeout和XMLHttpRequest 这两个webAPI
setTimeout定时器
会返回一个整数(定时器的编号),可以通过这个编号来取消定时器
浏览器实现定时器
在事件循环系统中,所有运行在主线程(渲染线程)中的任务都需要需要先添加到消息队列中,然后再根据顺序依次执行队列中的任务。
典型的事件:
- 接收HTML文档,渲染引擎就会将“解析DOM”事件添加到队列中
- 改变web页面的窗口大小,当做“重新布局”事件添加到队列中
- 触发垃圾回收机制,当做“垃圾回收”任务添加队列中
- 执行一段异步代码,也是将执行任务添加到消息队列中
也就是说执行一段异步代码,首先会将任务添加到消息队列中。而通过定时器设置的回调函数,是通过一段时间间隔来执行的。为了确保在正确的时间内执行回调函数,不能将回调函数添加到消息队列中。
因此,出现了异步队列(真正是一个hashmap),这个队列中维护了需要延迟执行的任务。所以,当调用setTimeout时,渲染进程会将该定时器的回调任务添加到异步队列中(记录当前时间戳、延迟时间以及回调函数),等到当前执行的任务执行结束之后,就会执行该异步队列中的任务(根据当前的时间计算出到期的任务,一次执行任务),执行结束,就会到下一个循环过程(消息队列获取任务,重新开始)
使用setTimeout注意事项
- 如果当前任务执行时间过久,会影响定时器任务的执行
function foo() {setTimeout(() => {console.log('setTimeout')}, 0)// 当前任务循环5000 执行时间可能过长for(let i = 0; i < 5000; i++) {console.log(i)}}
- 如果setTimeout存在嵌套调用,系统会设置最短时间间隔为4毫秒
function cb() { setTimeout(cb, 0)}setTimeout(cb, 0)
如果嵌套调用5次以上,之后每次调用的最小时间间隔为4毫秒(设置4毫秒以下),系统会判定该函数阻塞了
- 未激活的页面,setTimeout执行最小间隔为1000毫秒
如果未激活的页面或者处于后台的页面使用setTimeout时,最小间隔的时间为1s,目的是降低耗电量以及优化后台页面加载损耗
- 延迟执行的最大时间间隔
那就是 Chrome、Safari、Firefox 都是以 32 个 bit 来存储延时值的,32bit 最大只能存放的数字是 2147483647 毫秒,这就意味着,如果 setTimeout 设置的延迟值大于 2147483647 毫秒(大约 24.8 天)时就会溢出,那么相当于延时值被设置为 0,这导致定时器会被立即执行
- 回调函数中this
var obj = {a: 2,foo: function() {console.log('foo', this.a)}}setTimeout(obj.foo, 0) // foo undefined// 改进方式 1. bindsetTimeout(obj.foo.bind(obj), 0) // bind// 改进方式 2. =>setTimeout(() => {obj.foo()}, 0)
事件循环XMLHttpRequest
回调函数和系统调用栈 回调函数都不会陌生,它有两种方式: 同步回调和异步回调
- 同步回调 - 主函数中执行
function main(cb) {var a = 9console.log(a + 9)cb()console.log(a + 8)}function foo() (console.log(6))main(foo)
- 异步回调 = 主函数之外执行
function main(cb) {var a = 9console.log(a + 9)setTimeout(cb, 0)console.log(a + 8)}function foo() (console.log(6))main(foo)
XMLHttpRequest 运行机制
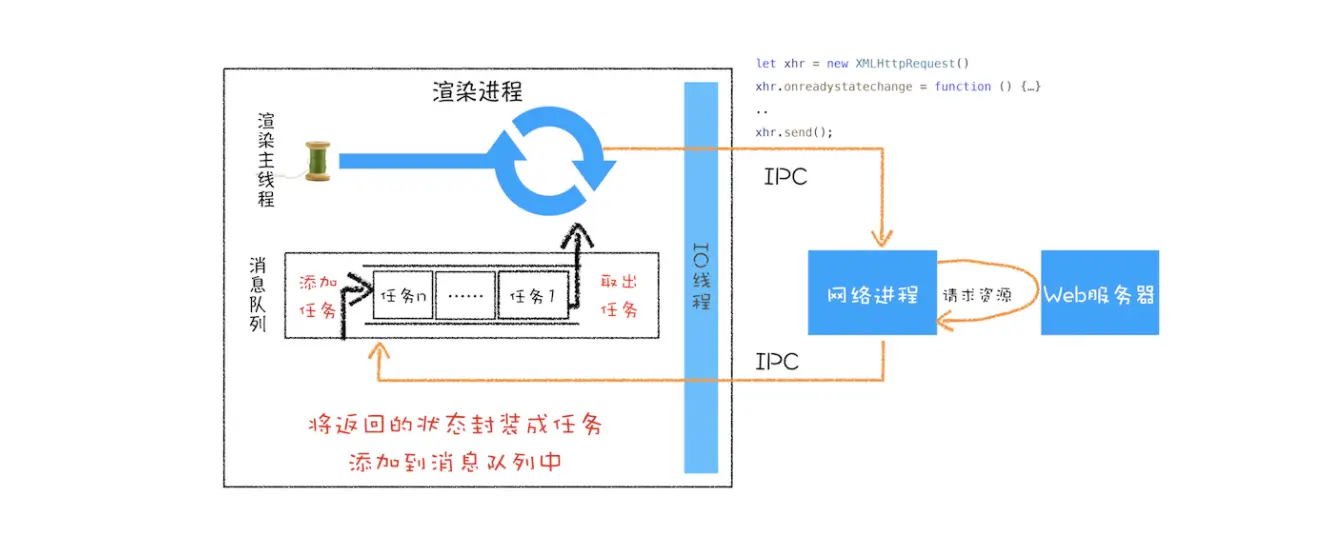
上图是XMLHttpRequest的总执行图, 下面看XMLHttpRequest的详细用法
function fetchData(url) {// 1. create xmlHttpRequset Objectlet xhr = new XMLHttpRequest()// 2. register callback fucntionxhr.onreadystatechange = function() {switch(xhr.readyState) {case 0: // 请求未初始化console.log('请求未初始化');breakcase 1: // openedconsole.log('opened');breakcase 2: // headers_receivedconsole.log('headers_received');breakcase 3: // loadingconsole.log('loading');breakcase 4: // DONEconsole.log('DONE');if(this.status == 200 || this.status == 304) {conosle.log(this.responseText)}break}}xhr.ontimeout = function(e) { console.log('ontimeout' )}xhr.onerror = function(e) { console.log('onerror' )}// 3. open requestxhr.open('Get', url, true) // create async request// 4. config paramxhr.timeout = 3000 // set timeoutxhr.responseType = 'text' // set response data typexhr.setRequestHeader('X_Test', 'time.cn')// 5. send requestxhr.send()}
使用XMLHttpRequest的问题
- 跨域问题 由于浏览器的安全策略以及同源策略限制,只能请求同源的服务地址
- HTTPS混入问题 HTTPs页面中使用了HTTP资源,包括图片,视频等,这时浏览器会发出警告
宏任务和微任务
上述学习了页面的运转是由消息队列和循环系统来驱动的,通过setTimeout和XMLHTTPRequest两个webAPI深入了解了消息队列(包括异步队列),这些队列中会有很多的任务,而这些任务都是宏任务。随着浏览器的应用越来越广泛,对实时性和效率要求越来越高。
而这些实时性和效率的出现,也就随之出现了微任务,微任务可以在实时性和效率之间做一个权衡。
但是,什么技术会用到微任务呢,或者说是微任务的应用场景有哪些呢?是怎么样权衡实时性和效率之间的平衡的呢?
带着这些问题来学习一些宏任务和微任务。
宏任务
页面中的大部分任务都是在主线程上执行的,这些任务包括:
- 渲染事件 - 解析DOM 计算布局 绘制
- 用户交互 - 点击 页面滚动
- JS脚本执行
- 网络请求、文件文件读写完成
为了协调这些任务有条不紊的执行,页面进程引进了消息队列和事件循环系统。主进程采用for循环,不断的从消息队列或者延迟队列中取出任务并执行任务。
这些任务就是宏任务
宏任务的时间粒度是比较大的,如果遇到一些对实时性要求比较高的任务(实时监听DOM),宏任务并不能满足,因此产生了微任务
微任务
微任务就是一个需要执行的异步函数,执行时机是在主函数执行结束之后,当前宏任务结束之前
结合V8层面理解微任务
遇到一段JS代码,V8会创建全局上下文,同时创建微任务队列用来存放微任务,在当前宏任务执行的过程中,会产生多个微任务,这个微任务队列是给V8引擎背部使用的,JS不能调用
微任务产生时机和执行时机
- 产生时机 - 现代浏览器
- 使用MutationObserve监听某个DOM节点,通过JS修改这个节点,DOM节点发生变化,就会产生DOM变化的微任务
- 使用Promise 调用Promise.resolve 和 Promise.reject
- 执行时机
在当前宏任务中JS执行快完成时,就在JavaScript引擎准备退出全局执行上下文并清空调用栈的时候,JS引擎会检查全局上下文中的微任务队列,然后按照顺序执行队列中的任务,执行微任务的时间点检查点
如果在执行微任务的同时,产生了新的微任务,则将改微任务添加到微任务队列中,V8引擎会循环执行微任务队列
直观的看个例子
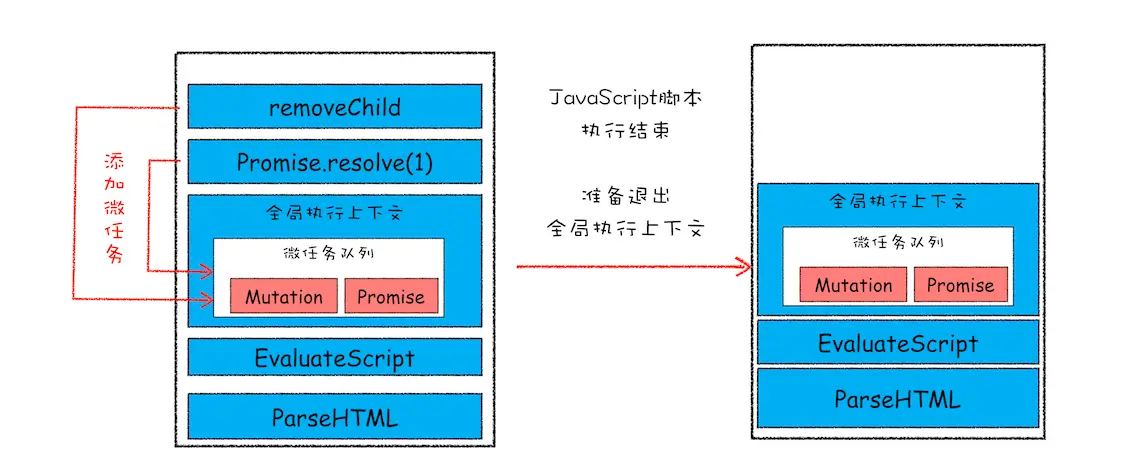
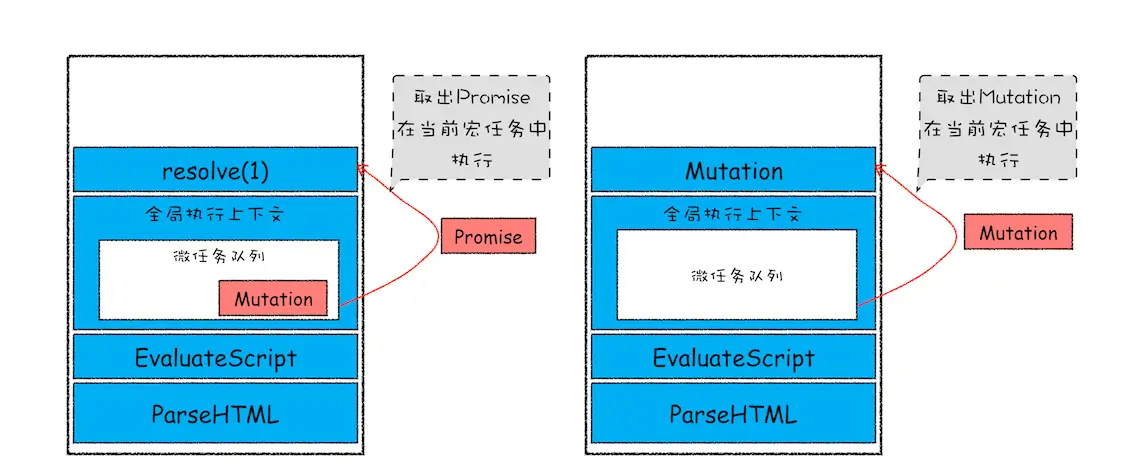
从上述可以得到以下结论:
- 微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列
- 微任务执行的时长,会影响当前宏任务的执行时长。
- 在一个宏任务中创建了一个用于回调的宏任务和微任务,无论什么情况下,微任务都会早于宏任务执行
监听DOM变化
随着现在web应用的复杂度提升,对页面的性能要求高的前提下,对于DOM的操作也逐渐的再更新。 早期对于页面DOM的监听,是使用轮询的方式,使用定时器来检测DOM是否有变化。后来引入了mutationEvent,采用观察者模式。之后又引入了mutationObserver,解决了mutationEvent所带来的的问题
- 轮询的方式 - 带来的问题
- 定时器的设置时长不确定,太长浪费时间成本,DOM相应不及时
- 设置时间太短,浪费无用的工作检查DOM
- mutationEvent - 带来的问题
- 采用观察者模式,DOM一变化,调用对应的回调更新,这种回调是同步回调
- 一旦一次动态修改多个节点内容,就会触发多个回调,每个回调执行时间固定的话,那更新DOM的总共耗时就会变的很长,最终会导致页面性能的问题
- mutationObserver
- 将mutationEvent的回调方式改变成了异步,不用每次去触发异步调用,而是等多次DOM操作之后,再去触发DOM更新
- 采用
异步 + 微任务策略 - 异步解决了性能问题
- 微任务解决了实时性的问题
mutationObserver和微任务联系
mutationObserver将DOM更新封装成异步。当前宏任务中有操作DOM的操作,就会将这些更新DOM的异步回调添加到当前宏任务中的微任务队列中,当前宏任务执行结束之后(检查点),就会执行这些微任务,也就是更新微任务的回调
Promise 告别回调
promise已经成为了前端解决异步的主力,接下来具体的学习promise
异步编程的问题-代码逻辑不连续
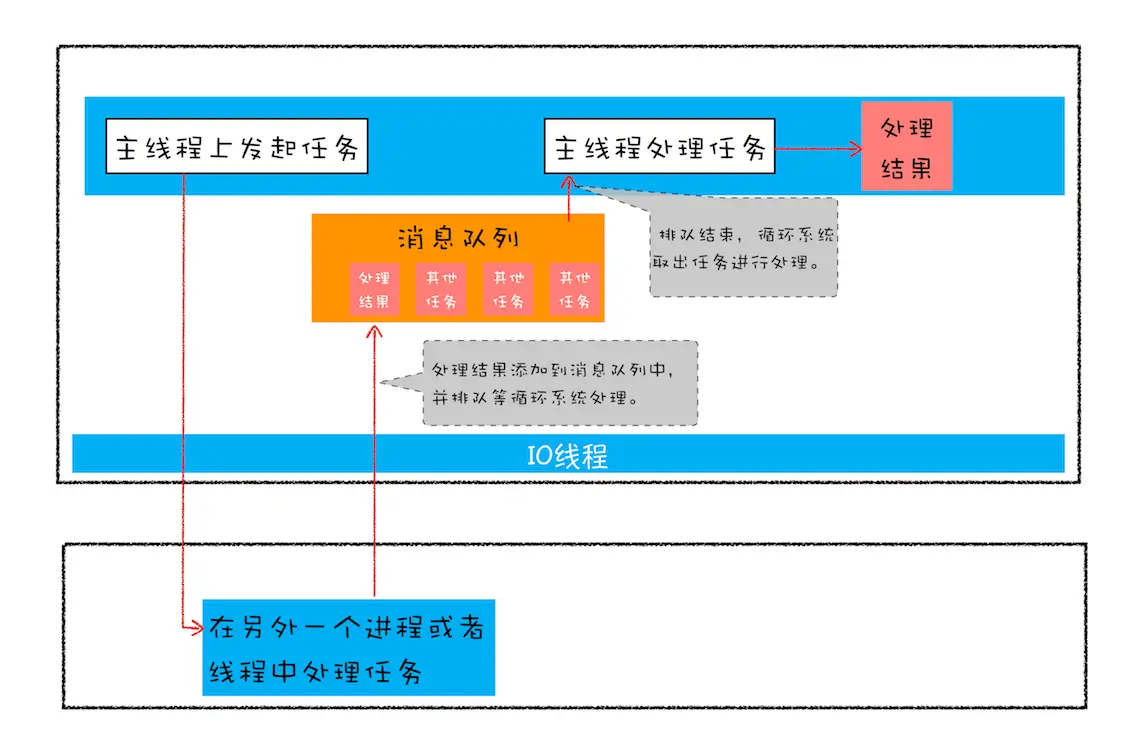
上述是web异步编程模型 接下来看下传统的异步回调带来的问题
function requset(url) {return {url: url,method: 'GET',timeout: 3000,aync: true,responseType: 'text',}}// 封装XMLHttpRequest 请求function Fetch(request, resolve, reject) {var xhr = new XMLHttpRequset()xhr.onreadystatechange = function() {if(this.status == 200) {resolve(xhr.respose)}}xhr.ontimeout = function() { reject() }xhr.onerror = function() { reject() }xhr.open(requset.method, request.url, request.sync)xhr.timeout = request.timeoutxhr.responseType = request.responseTypexhr.send()}// 调用封装请求Fetch(request('/api/list'), (data) => {console.log(data)}, (error) => {console.log(error)})
截止目前,封装后的请求对于单个请求或者简单请求是完美的,但是如果遇到嵌套调用,如果有很多嵌套时,就会陷入回调地狱,比如下面的代码:
Fetch(request('/api/list'), (data) => {console.log(data)Fetch(request('/api/list'), (data) => {console.log(data)Fetch(request('/api/list'), (data) => {console.log(data)}, (error) => {console.log(error)})}, (error) => {console.log(error)})}, (error) => {console.log(error)})
嵌套层级一多,就会给人一种凌乱的感觉,代码结构很乱。所以,需要解决这种问题。
- 嵌套层级多 - 解决嵌套调用
- 任务的不确定性 每次请求都会有错误处理 - 合并错误处理
随着这两个问题出现,Promise就登场了,下面代码是怎么解决这两个问题的
// 将XMLHttpRequest 使用Promise封装function XFetch(request) {return new Promise((resolve, reject) => {var xhr = new XMLHttpRequset()xhr.onreadystatechange = function() {if(this.status == 200 && this.readyStatus === 4) {resolve(this.response)}else {reject({error: this.response})}}xhr.ontimeout = function() { reject() }xhr.onerror = function() { reject() }xhr.open(requset.method, request.url, request.sync)xhr.timeout = request.timeoutxhr.responseType = request.responseTypexhr.send()})}let x1 = XFetch(request('/api/list'))let x2 = x1.then(res => {console.log(res)return XFetch(request('/api/list?type=1'))})x2.then(res => {console.log(res)}).catch(err => {console.log(err)})
Promise 怎么解决嵌套回调问题
- Promise 实现了回调函数延时绑定
// 执行业务逻辑function executor(resolve, reject) {resolve(2)}let x1 = new Promise(executor)// 延迟绑定回调函数function cbResolve(val) {console.log(val)}// 通过then延时绑定x1.then(cbResolve)
2. 回调函数返回值穿透到最外层
// 执行业务逻辑function executor(resolve, reject) {resolve(2)}let x1 = new Promise(executor)// 延迟绑定回调函数function cbResolve(val) {console.log(val)return new Promise((resolve, reject) => {resolve(300 + val)})}// 通过then延时绑定 返回promise对象 将内部返回值穿透到最外层let x2 = x1.then(cbResolve)x2.then(result => {console.log(result)})
Promise和微任务
下面简单的实现promise, 了解回调函数的延迟绑定技术,以及了解promise的内部的原理
function BPromise(executor) {let _onResolve = nulllet _onReject = nullthis.then = function(onresolve, onreject) {_onResolve = onresolve}function resolve(val) {// 设置延迟绑定回调// promise将定时器 改成了微任务的方式setTimeout(() => {_onResolve()}, 0)}executor(resolve, null)}function executor(resolve, reject) {resolve(200)}let bpromise = new BPromise(executor)bpromise.then(val => {console.log(val)})
async/await 同步的方式
使用promise能够很好的解决回调地狱的问题,但是也会有语义化不明显的问题,处理流程复杂或者业务逻辑多,使用then就会带来不能明显表示执行流程,比如嵌套调用api层级较多时。
基于这个原因,ES7引入了async和await, 在不阻塞主线程的情况下使用同步代码实现异步访问资源的能力,是代码逻辑更清晰
async function foo() {let result = await fetch(url)let resultall = await fetch(url1)conosle.log(result)conosle.log(resultall)}
使用这种方式,可以以同步的方式获取资源内容,很直观的代码编写方式。 下面来进一步学习,底层是怎么工作的
生成器和协程
- 生成器函数 - 它是一个带星号的函数,可以暂停和恢复执行的
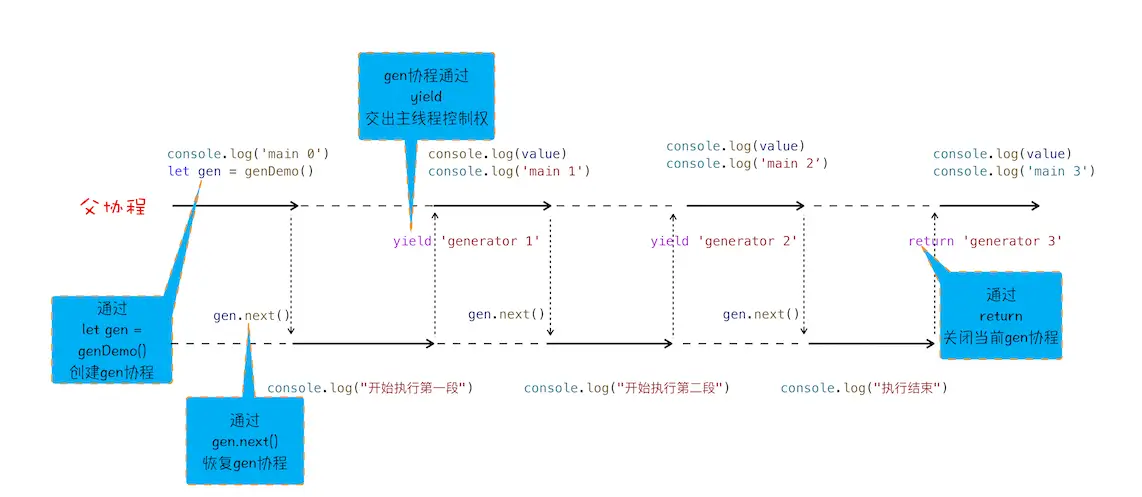
function* genDemo() {console.log('first executer')yield 'generator 1'console.log('second executer')yield 'generator 2'console.log('third executer')yield 'generator 3'console.log('end executer')return 'generator 4'}console.log('start main0')let gen = genDemo()console.log(gen.next().value)console.log('start main1')console.log(gen.next().value)
可以从打印结果看到,generator函数并不是一次性执行结束的,使用方式:
- 遇到
yield的关键字,JS引擎就会返回关键字后面的内容给外部。并暂定该函数的执行 - 外部函数通过
next()方法恢复函数的执行
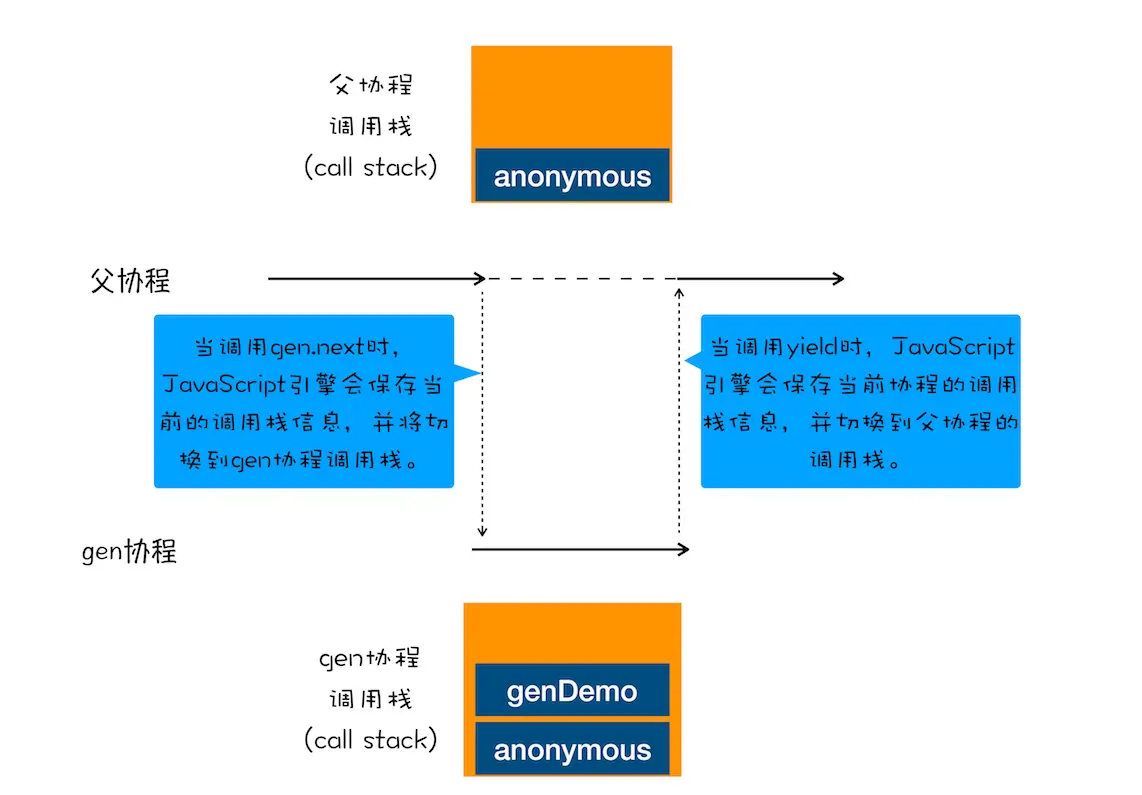
JS 引擎是如何实现一个函数暂停和恢复的
首先要了解协程的概念: 是一种比线程更加轻量级的存在。
- 协程看做是主线程上的任务
- 一个线程可以存在多个协程,在线程上只能执行一个协程
- 如果A协程启动B协程,就把A协程称为B协程的父协程
- 协程是由用户态控制的
- 通过return退出协程
可以看一下协程的执行图